Should I Scrape This? Planning Notes on Inspecting Websites
Web scraping can vary between wildly hard (purposefully or otherwise) and being the notch below an open API to extract data. However, there are often some hints you can use to check whether or not a particular site will be one of the easy or hard ones.
Obligatory disclaimer about web scraping: some sites, and owners of those sites, do not appreciate being scraped. This might be because scraping effectively is stealing their main commercial product; others might be because of too many inconsiderate scrapers flinging minor DDOS attacks every time they test their scraping tools. Be a mindful scraper, check the site's robots.txt file, and be mindful of the owners and purpose of the site itself.
1. Not all APIs are public
Just because a data provider doesn't have a public API (though if they have, you should use it), that doesn't mean they aren't using a database organised in a similar way to provision data to users on their site. Sites with more modern protocols tend to fall into this category, which tend to have the following features;
- The URL paths are well structured
- Data objects referred to by codes in the code, not their names (this may be another field).
- Browsing through the pages, the layouts tend to approach identical.
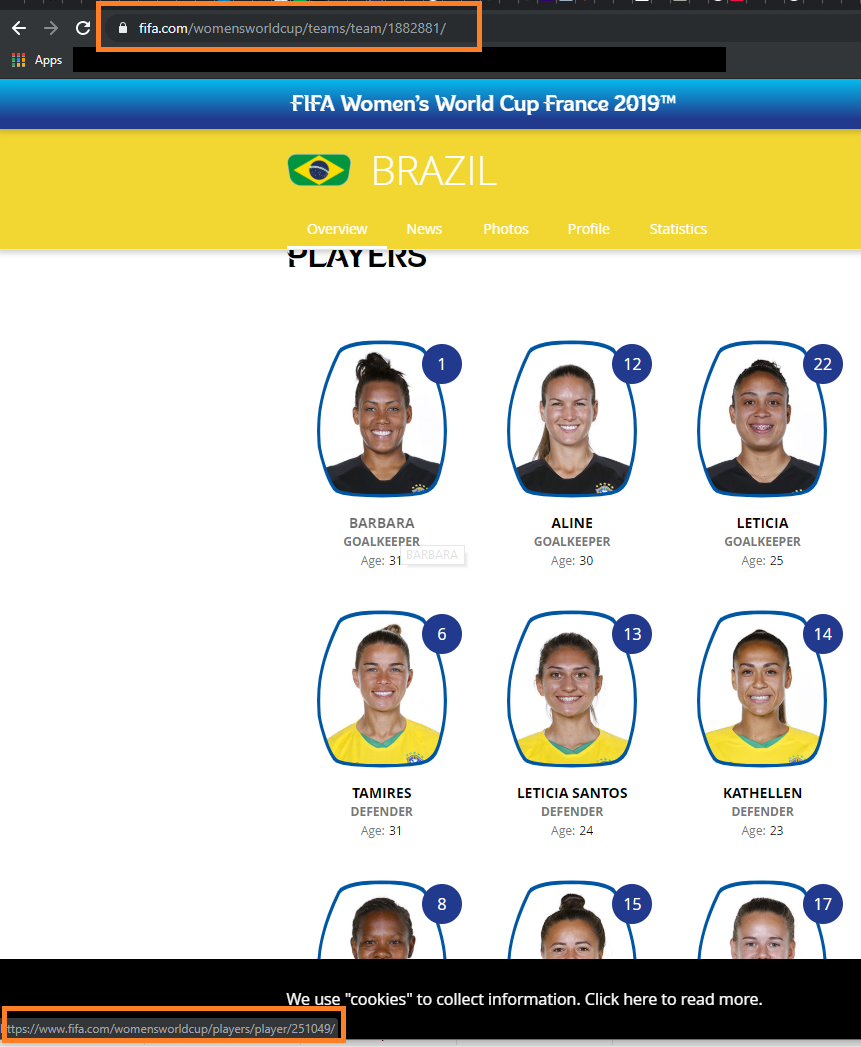
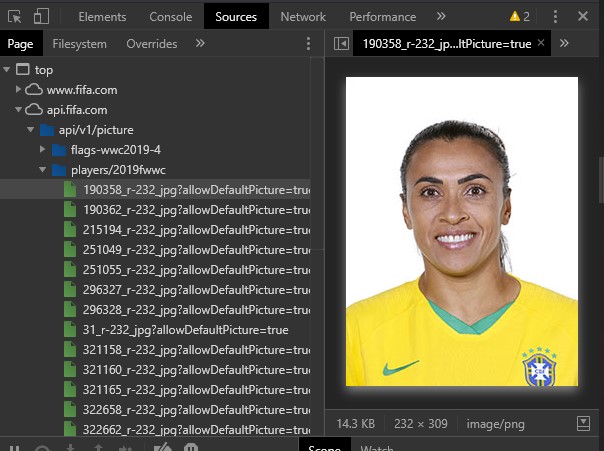
FIFA is a good example of this. Looking at their site for the Women's World Cup, teams, players and games tend to follow specific patterns of presentations in their web pages, because as you can see from the URLs, the data is following a similar kind of pattern to basic API calls. If we open the web console and check out the Sources used in the page, we can see that this is actually the case; FIFA is using an internal API to supply pictures (at a very minimum) to the page.
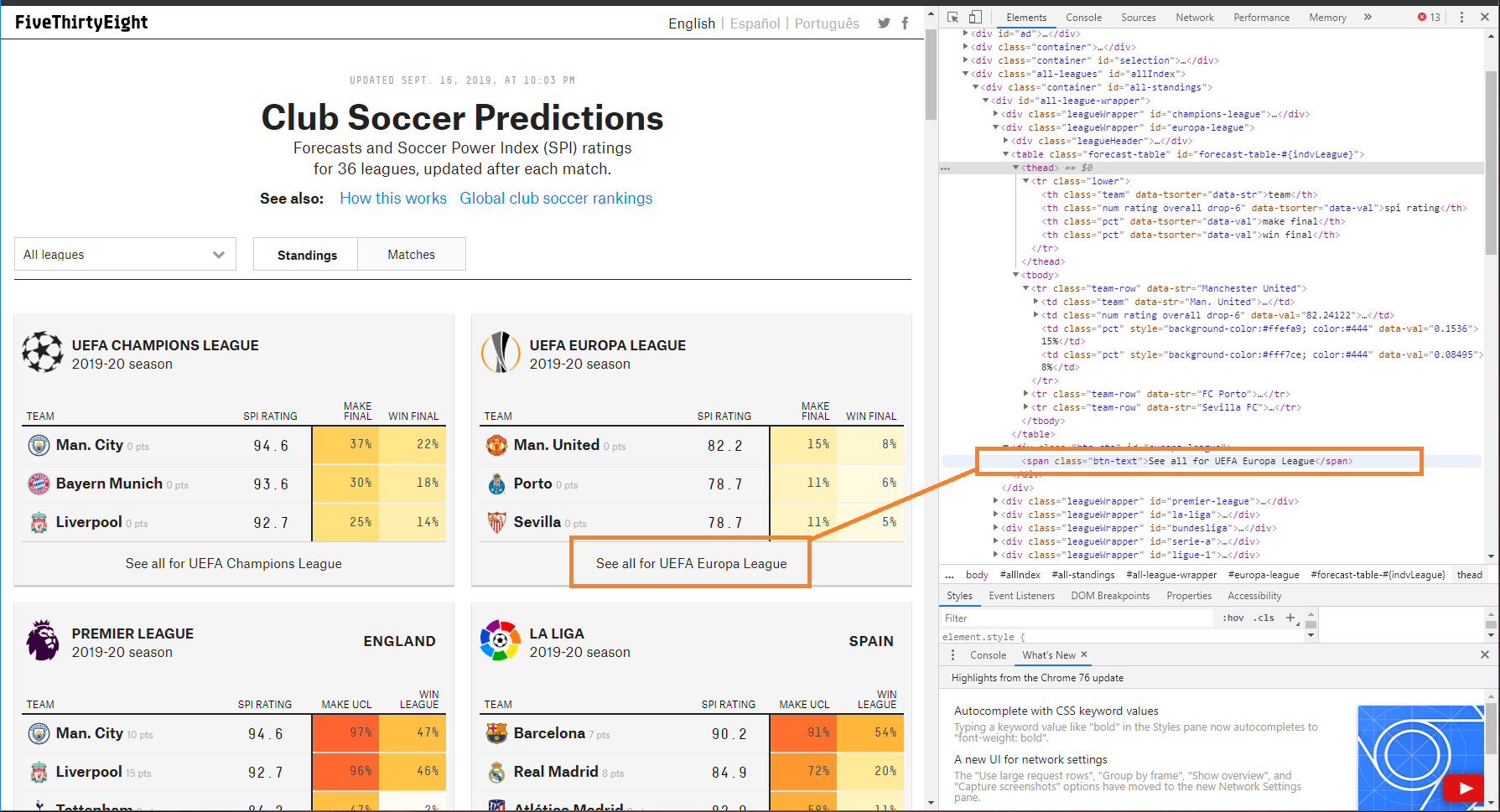
2. There aren't loads of jazzy JS and other friends plugins
Add-ins which enhance user experience, whether ranging from chart presentation like D3, or setting specific formats of an experience object like AML, can create speed bumps for any desired scraping. This is because data objects are often obscured by other frames and objects, making them harder to parse in the first place, and introducing layers of potential variation between one page and another, foiling attempts to create templates. Consider this example from FiveThirtyEight, with football predictions for selected leads:
Inspecting the site, one might hope it would be easy to go in and out to each table and obtain predictions for all the leagues. However, because the link to view the whole table doesn't work like a standard h ref html tag, you might be sorting through the page code for a long time looking for the links, or be employing more sophisticated tools which can simulate page interaction (such as testing tools) in order to load all the data you need.
3. The object layouts and content standards are actually identical
During training, when we were learning web scraping at The Data School, a colleague and I had to scrape some financial information from NASDAQ listed companies on Wikipedia. The information we needed was only that which exists in those little info panels we have come to know and love. These panels look essentially the same to humans, but under the hood, and to things which can't read (like machines), they're not.
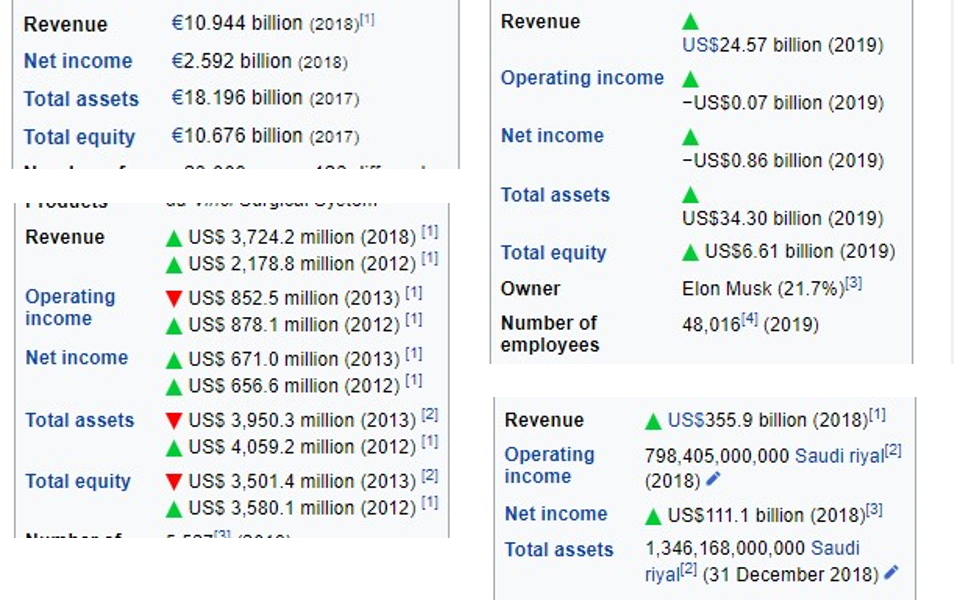
When sites deliver information in the manner of #1, the content is being delivered to a framework replicated on each page. So scrape one page in a category, and you've probably got 90% of the category if you needed it, as the data input must conform to certain principles for however it's stored. Flexible sites like Wikipedia however, are human edited and do not enforce rigid principles in the same way a database would. My colleague and I struggled to normalise the data in the time limit that we had (which was about 3 hours) because of the different things we had to accommodate, such as multiple dates, different icons, and different ways of writing numbers. Sites like this illustrate the difference between humans grasping comprehension (which can tolerate these variances) and machines "reading", which cannot unless programmed to accommodate them specifically.
Hopefully this provides some help to people planning scraping projects in the future!